GroupVariableImportanceMixin#
- class hidimstat.base_variable_importance.GroupVariableImportanceMixin(features_groups=None)[source]#
Bases:
objectMixin class for adding group functionality to variable importance methods. This class provides functionality for handling grouped features in variable importance calculations, enabling group-wise selection and importance evaluation.
- Parameters:
- features_groups: dict or None, default=None
Dictionary mapping group names to lists of feature column names/indices. If None, each feature is treated as its own group.
- Attributes:
- n_features_groups_int
Number of feature groups.
- _features_groups_idsarray-like
List of feature indices for each group.
Methods
fit(X, y=None)
Identifies feature groups and validates input data structure.
_check_fit()
Verifies if the instance has been fitted.
_check_compatibility(X)
Validates compatibility between input data and fitted groups.
- fit(X, y=None)[source]#
Base fit method for perturbation-based methods. Identifies the groups.
- Parameters:
- X: array-like of shape (n_samples, n_features)
The input samples.
- y: array-like of shape (n_samples,)
Not used, only present for consistency with the sklearn API.
- Returns:
- selfobject
Returns the instance itself.
Examples using hidimstat.base_variable_importance.GroupVariableImportanceMixin#
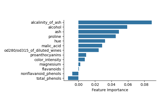
Conditional Feature Importance (CFI) on the wine dataset

Leave-One-Covariate-Out (LOCO) feature importance with different regression models

Conditional vs Marginal Importance on the XOR dataset
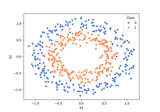

Measuring Individual and Group Variable Importance for Classification

Pitfalls of Permutation Feature Importance (PFI) on the California Housing Dataset