Note
Go to the end to download the full example code.
Leave-One-Covariate-Out (LOCO) feature importance with different regression models#
This example demonstrates how to compare LOCO feature importance [Williamson et al.[1]] across different predictive models on the same regression dataset. LOCO is model-agnostic and can be applied to any predictive model. Here, we use a linear model, a random forest, a neural network, and a support vector machine. We compare the models based on their predictive performance (R2 score) and the LOCO feature importance they yield.
Loading and preparing the data#
We begin by simulating a regression dataset with 10 features, 5 of which are in the support set, meaning they contribute to generating the outcome. In this example, we use a simulated dataset to have access to the true support set of features and evaluate how well the different models identify these important features. The data is then split into training and test sets. These sets are used both to fit the predictive models and within the LOCO procedure, which refits models on subsets of features that exclude the feature of interest.
from sklearn.datasets import make_regression
from sklearn.model_selection import train_test_split
X, y, beta = make_regression(
n_samples=300,
n_features=10,
n_informative=5,
random_state=0,
coef=True,
noise=10.0,
)
# We convert the coefficients of the data-generating process into a binary array
# indicating the true support set of features.
beta = beta != 0
X_train, X_test, y_train, y_test = train_test_split(
X,
y,
test_size=0.2,
random_state=0,
shuffle=True,
)
Fitting models and computing LOCO feature importance#
We define a list of predictive models to compare. We use RidgeCV for linear regression, RandomForestRegressor for a tree-based model, MLPRegressor for a neural network, and SVR for a support vector machine, with RBF kernel. We then fit each model on the training data, compute the LOCO feature importance on the test data, and store the results in a DataFrame for comparison.
import pandas as pd
from sklearn.ensemble import RandomForestRegressor
from sklearn.linear_model import RidgeCV
from sklearn.neural_network import MLPRegressor
from sklearn.svm import SVR
from hidimstat import LOCO
models_list = [
RidgeCV(),
RandomForestRegressor(n_estimators=150, random_state=0),
MLPRegressor(
hidden_layer_sizes=(8),
random_state=0,
max_iter=500,
learning_rate_init=0.1,
),
SVR(kernel="linear"),
]
df_list = []
for model in models_list:
# Fit the full model
model = model.fit(X_train, y_train)
loco = LOCO(model)
# For each feature, remove it from the dataset, refit the model, and compute LOCO
# importance. This process is repeated for all features to assess their individual
# contributions.
loco.fit(X_train, y_train)
importances = loco.importance(X_test, y_test)["importance"]
df_list.append(
pd.DataFrame(
{
"feature": list(range(X.shape[1])),
"importance": importances,
"model": model.__class__.__name__,
"R2 score": model.score(X_test, y_test),
}
)
)
The predictive performance of the models can be compared using their R2 scores. This helps assess how effectively each model captures the underlying data-generating process.
df_plot = pd.concat(df_list)
df_plot.groupby("model").mean()["R2 score"].to_frame()
Visualization of LOCO feature importance#
Finally, we visualize the LOCO feature importance for each model using a horizontal bar plot. The true support features are highlighted in the plot with a green shaded background.
import matplotlib.pyplot as plt
import seaborn as sns
ax = sns.barplot(
data=df_plot,
y="feature",
x="importance",
hue="model",
palette="muted",
orient="h",
)
sns.despine()
for i, support in enumerate(beta):
if support != 0:
ax.axhspan(
i - 0.45,
i + 0.45,
color="tab:olive",
alpha=0.3,
zorder=-1,
label="True Support" if i == 1 else None,
)
ax.legend()
plt.show()
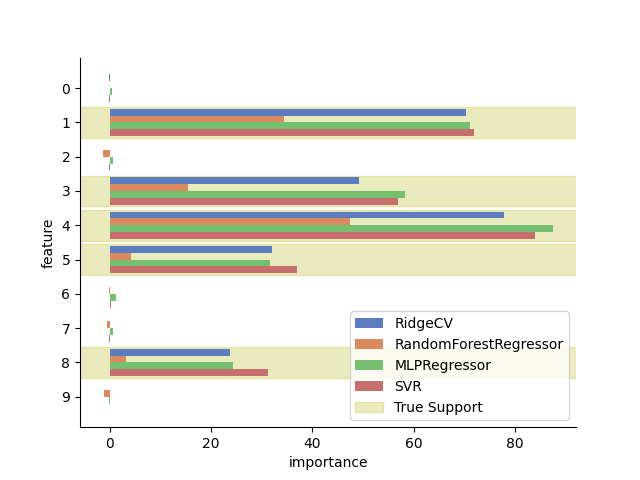
The plot shows that the different models all identify the true support features and assign them higher importance scores. However, the magnitude of the importance scores varies across models. It can be observed that models with a greater predictive performance (higher R2 score) tend to assign higher importance scores to the true support features.
References#
Total running time of the script: (0 minutes 23.202 seconds)