Note
Go to the end to download the full example code.
Pitfalls of Permutation Feature Importance (PFI) on the California Housing Dataset#
In this example, we illustrate the pitfalls of using permutation feature importance (PFI) on the California housing dataset. PFI measures the importance of a variable. However, it does not measure conditional importance and does not provide statistical control over the risk of making false discoveries, i.e., the risk of declaring a variable as important when it is not.
import matplotlib.pyplot as plt
import numpy as np
import pandas as pd
import seaborn as sns
from matplotlib.lines import Line2D
from scipy.stats import ttest_1samp
from sklearn.base import clone
from sklearn.compose import TransformedTargetRegressor
from sklearn.datasets import fetch_california_housing
from sklearn.linear_model import RidgeCV
from sklearn.metrics import r2_score
from sklearn.model_selection import KFold, train_test_split
from sklearn.neural_network import MLPRegressor
from sklearn.pipeline import make_pipeline
from sklearn.preprocessing import StandardScaler
from hidimstat import CPI, PFI
from hidimstat.conditional_sampling import ConditionalSampler
rng = np.random.RandomState(0)
Load the California housing dataset and add a spurious feature#
The California housing dataset is a regression dataset with 8 features. We add a spurious feature that is a linear combination of 3 features plus some noise. The spurious feature does not provide any additional information about the target.
dataset = fetch_california_housing()
X_, y_ = dataset.data, dataset.target
# only use 2/3 of samples to speed up the example
X, _, y, _ = train_test_split(X_, y_, test_size=0.6667, random_state=0, shuffle=True)
redundant_coef = rng.choice(np.arange(X.shape[1]), size=(3,), replace=False)
X_spurious = X[:, redundant_coef].sum(axis=1)
X_spurious += rng.normal(0, scale=np.std(X_spurious) * 0.5, size=X.shape[0])
X = np.hstack([X, X_spurious[:, np.newaxis]])
feature_names = dataset.feature_names + ["Spurious"]
print(f"The dataset contains {X.shape[0]} samples and {X.shape[1]} features.")
# Compute the correlation matrix
correlation_matrix = np.corrcoef(X, rowvar=False)
# Plot the lower triangle of the correlation matrix
fig, ax = plt.subplots()
mask = np.triu(np.ones_like(correlation_matrix, dtype=bool))
sns.heatmap(
correlation_matrix,
mask=mask,
cmap="coolwarm",
annot=True,
fmt=".2f",
square=True,
cbar_kws={"shrink": 0.8},
ax=ax,
)
ax.set_title("Correlation Matrix")
ax.set_yticks(
np.arange(len(feature_names)) + 0.5, labels=feature_names, fontsize=10, rotation=45
)
ax.set_xticks(
np.arange(len(feature_names)) + 0.5, labels=feature_names, fontsize=10, rotation=45
)
plt.tight_layout()
plt.show()
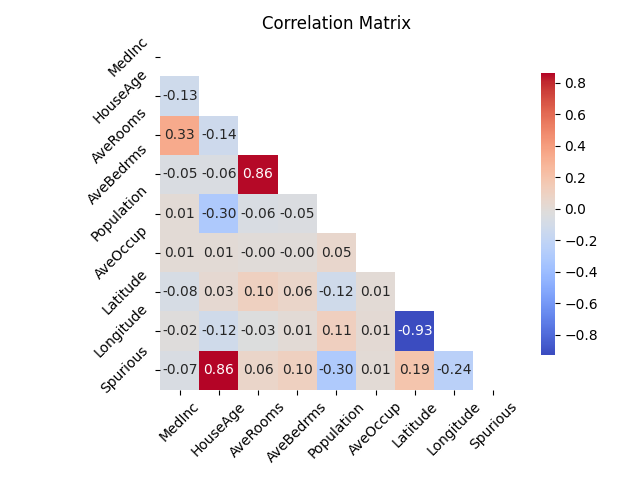
The dataset contains 6879 samples and 9 features.
Fit a predictive model#
We fit a neural network model to the California housing dataset. PFI is a model-agnostic method, we therefore illustrate its behavior when using a neural network model.
fitted_estimators = []
scores = []
model = TransformedTargetRegressor(
regressor=make_pipeline(
StandardScaler(),
MLPRegressor(
random_state=0,
hidden_layer_sizes=(32, 16, 8),
early_stopping=True,
learning_rate_init=0.01,
n_iter_no_change=5,
),
),
transformer=StandardScaler(),
)
kf = KFold(n_splits=5, shuffle=True, random_state=0)
for train_index, test_index in kf.split(X):
X_train, X_test = X[train_index], X[test_index]
y_train, y_test = y[train_index], y[test_index]
model_c = clone(model)
model_c = model_c.fit(X_train, y_train)
fitted_estimators.append(model_c)
y_pred = model_c.predict(X_test)
scores.append(r2_score(y_test, y_pred))
print(f"Cross-validation R2 score: {np.mean(scores):.3f} ± {np.std(scores):.3f}")
Cross-validation R2 score: 0.734 ± 0.041
Measure the importance of variables using the PFI method#
We use the PermutationFeatureImportance class to compute the PFI in a cross-fitting way. We then derive a p-value from importance scores using a one-sample t-test. As shown in the figure below, the PFI method does not provide valid p-values for testing conditional importance, as it identifies the spurious feature as important.
permutation_importances = []
conditional_permutation_importances = []
for i, (train_index, test_index) in enumerate(kf.split(X)):
X_train, X_test = X[train_index], X[test_index]
y_train, y_test = y[train_index], y[test_index]
model_c = fitted_estimators[i]
# Compute permutation feature importance
pfi = PFI(
model_c,
n_permutations=50,
random_state=0,
)
pfi.fit(X_test, y_test)
permutation_importances.append(pfi.importance(X_test, y_test)["importance"])
permutation_importances = np.stack(permutation_importances)
pval_pfi = ttest_1samp(
permutation_importances, 0.0, axis=0, alternative="greater"
).pvalue
# Define a p-value threshold
pval_threshold = 0.05
# Create a horizontal boxplot of permutation importances
fig, ax = plt.subplots()
sns.barplot(
permutation_importances,
orient="h",
color="tab:blue",
capsize=0.2,
)
ax.set_xlabel("Permutation Importance")
# Add asterisks for features with p-values below the threshold
for i, pval in enumerate(pval_pfi):
if pval < pval_threshold:
ax.scatter(
np.max(permutation_importances[:, i]) + 0.01,
i,
color="red",
marker="*",
label="pvalue < 0.05" if i == 0 else "",
)
ax.axvline(x=0, color="black", linestyle="--")
# Add legend for asterisks
ax.legend(loc="upper right")
sns.despine(ax=ax)
ax.set_yticks(range(len(feature_names)), labels=feature_names)
fig.tight_layout()
plt.show()
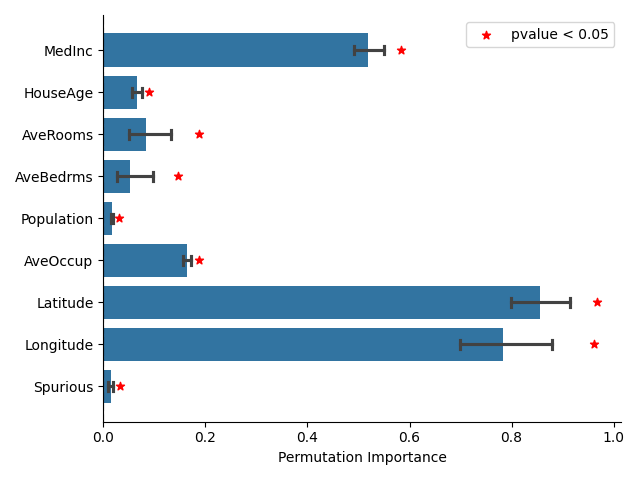
While the most important variables identified by PFI are plausible, such as the geographic coordinates or the median income of the block group, it is not robust to the presence of spurious features and misleadingly identifies the spurious feature as important.
A valid alternative: Condional permutation importance#
The ConditionalPermutationFeatureImportance class computes permutations of the feature of interest while conditioning on the other features. In other words, it shuffles the intrinsic information of the feature of interest while leaving the information that is explained by the other features unchanged. This method is valid for testing conditional importance. As shown below, it does not identify the spurious feature as important.
conditional_importances = []
for i, (train_index, test_index) in enumerate(kf.split(X)):
X_train, X_test = X[train_index], X[test_index]
y_train, y_test = y[train_index], y[test_index]
model_c = fitted_estimators[i]
# Compute conditional permutation feature importance
cpi = CPI(
model_c,
imputation_model_continuous=RidgeCV(alphas=np.logspace(-3, 3, 5)),
random_state=0,
n_jobs=5,
)
cpi.fit(X_test, y_test)
conditional_importances.append(cpi.importance(X_test, y_test)["importance"])
cpi_pval = ttest_1samp(
conditional_importances, 0.0, axis=0, alternative="greater"
).pvalue
df_pval = pd.DataFrame(
{
"pval": np.concatenate([pval_pfi, cpi_pval]),
"method": ["PFI"] * len(pval_pfi) + ["CPI"] * len(cpi_pval),
"variable": feature_names * 2,
"log_pval": -np.concatenate([np.log10(pval_pfi), np.log10(cpi_pval)]),
}
)
fig, ax = plt.subplots()
sns.barplot(
data=df_pval,
x="log_pval",
y="variable",
hue="method",
palette="muted",
ax=ax,
)
ax.axvline(x=-np.log10(pval_threshold), color="red", linestyle="--")
ax.set_xlabel("-$\\log_{10}(pval)$")
plt.tight_layout()
plt.show()
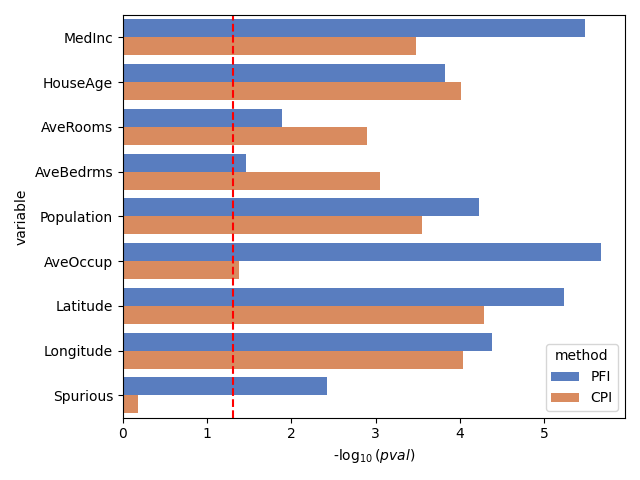
Contrary to PFI, CPI does not identify the spurious feature as important.
Extrapolation bias in PFI#
One of the main pitfalls of PFI is that it leads to extrapolation bias, i.e., it forces the model to predict from regions of the feature space that are not present in the training data. This can be seen on the california housing dataset, by comparing the original latitude and longitude values with the permuted values. Indeed, permuting the longitude values leads to generating combinations of latitude and longitude that fall outside of the borders of California and therefore are by definition not in the training data. This is not the case for the conditional permutation that generates perturbed but reasonable values of longitude.
X_train, X_test = train_test_split(
X,
test_size=0.3,
random_state=0,
)
conditional_sampler = ConditionalSampler(
model_regression=RidgeCV(alphas=np.logspace(-3, 3, 5)),
random_state=0,
)
conditional_sampler.fit(X_train[:, :7], X_train[:, 7])
X_test_sample = conditional_sampler.sample(
X_test[:, :7], X_test[:, 7], n_samples=1
).ravel()
# sphinx_gallery_thumbnail_number = 4
fig, ax = plt.subplots()
sns.histplot(
x=X_test[:, 6],
y=X_test[:, 7],
color="tab:blue",
ax=ax,
alpha=0.9,
)
sns.scatterplot(
x=X_test[:, 6],
y=X_test_sample,
ax=ax,
alpha=0.2,
c="tab:green",
)
sns.scatterplot(
x=X_test[:, 6],
y=rng.permutation(X_test[:, 7]),
ax=ax,
alpha=0.2,
c="tab:orange",
)
legend_elements = [
Line2D(
[0],
[0],
marker="o",
color="w",
markerfacecolor="tab:blue",
markersize=10,
label="Original",
),
Line2D(
[0],
[0],
marker="o",
color="w",
markerfacecolor="tab:orange",
markersize=10,
label="Permutation",
),
Line2D(
[0],
[0],
marker="o",
color="w",
markerfacecolor="tab:green",
markersize=10,
label="Conditional Permutation",
),
]
ax.legend(handles=legend_elements, loc="upper right")
ax.set_ylim(X[:, 7].min() - 0.1, X[:, 7].max() + 0.1)
sns.despine(ax=ax)
ax.set_xlabel("Latitude")
ax.set_ylabel("Longitude")
plt.show()
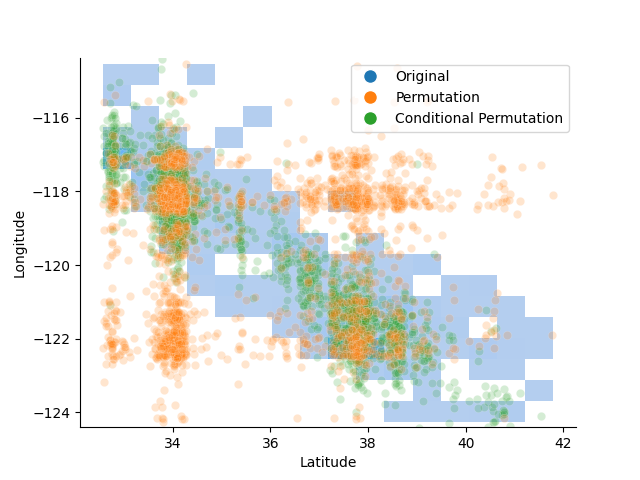
PFI is likely to generate samples that are unrealistic and outside of the training data, leading to extrapolation bias. In contrast, CPI generates samples that respect the conditional distribution of the feature of interest.
Total running time of the script: (0 minutes 16.816 seconds)