Note
Go to the end to download the full example code.
Support Recovery on fMRI Data#
This example compares methods based on Desparsified Lasso (DL) to estimate voxel activation maps associated with behavior, specifically decoder map support. All methods presented here provide statistical guarantees.
To demonstrate these methods, we use the Haxby dataset, focusing on the ‘face vs house’ contrast. We analyze labeled activation maps from a single subject to produce a brain map showing the discriminative pattern between these two conditions.
This example illustrates that in high-dimensional settings (many voxels), DL becomes impractical due to memory constraints. However, we can overcome this limitation using feature aggregation methods that leverage the spatial structure of the data (high correlation between neighboring voxels).
We introduce two feature aggregation methods that maintain statistical guarantees, though with a small spatial tolerance in support detection (i.e., they may identify null covariates “close” to non-null covariates):
- Clustered Desparsified Lasso (CLuDL): combines clustering (parcellation)
with statistical inference
- Ensemble Clustered Desparsified Lasso (EnCluDL): adds randomization
to the clustering process
EnCluDL is particularly powerful as it doesn’t rely on a single clustering choice. As demonstrated in Chevalier et al.[1], it produces relevant predictive regions across various tasks.
Imports needed for this script#
import resource
import warnings
import numpy as np
import pandas as pd
from matplotlib.pyplot import get_cmap
from nilearn import datasets
from nilearn.image import mean_img
from nilearn.maskers import NiftiMasker
from nilearn.plotting import plot_stat_map, show
from sklearn.cluster import FeatureAgglomeration
from sklearn.preprocessing import StandardScaler
from sklearn.feature_extraction import image
from sklearn.utils import Bunch
from hidimstat.ensemble_clustered_inference import (
clustered_inference,
clustered_inference_pvalue,
)
from hidimstat.ensemble_clustered_inference import (
ensemble_clustered_inference,
ensemble_clustered_inference_pvalue,
)
from hidimstat.desparsified_lasso import (
desparsified_lasso,
desparsified_lasso_pvalue,
)
from hidimstat.statistical_tools.p_values import zscore_from_pval
# Remmove warnings during loading data
warnings.filterwarnings(
"ignore", message="The provided image has no sform in its header."
)
# Limit the ressoruce use for the example to 5 G.
resource.setrlimit(resource.RLIMIT_AS, (int(5 * 1e9), int(5 * 1e9)))
n_job = 1
Function to fetch and preprocess Haxby dataset#
def preprocess_haxby(subject=2, memory=None):
"""Gathering and preprocessing Haxby dataset for a given subject."""
# Gathering data
haxby_dataset = datasets.fetch_haxby(subjects=[subject])
fmri_filename = haxby_dataset.func[0]
behavioral = pd.read_csv(haxby_dataset.session_target[0], sep=" ")
conditions = behavioral["labels"].values
session_label = behavioral["chunks"].values
condition_mask = np.logical_or(conditions == "face", conditions == "house")
groups = session_label[condition_mask]
# Loading anatomical image (back-ground image)
if haxby_dataset.anat[0] is None:
bg_img = None
else:
bg_img = mean_img(haxby_dataset.anat, copy_header=True)
# Building target where '1' corresponds to 'face' and '-1' to 'house'
y = np.asarray((conditions[condition_mask] == "face") * 2 - 1)
# Loading mask
mask_img = haxby_dataset.mask
masker = NiftiMasker(
mask_img=mask_img,
standardize="zscore_sample",
smoothing_fwhm=None,
memory=memory,
)
# Computing masked data
fmri_masked = masker.fit_transform(fmri_filename)
X = np.asarray(fmri_masked)[condition_mask, :]
return Bunch(X=X, y=y, groups=groups, bg_img=bg_img, masker=masker)
Gathering and preprocessing Haxby dataset for a given subject#
The preprocess_haxby function make the preprocessing of the Haxby dataset, it outputs the preprocessed activation maps for the two conditions ‘face’ or ‘house’ (contained in X), the conditions (in y), the session labels (in groups) and the mask (in masker). You may choose a subject in [1, 2, 3, 4, 5, 6]. By default subject=2.
[get_dataset_dir] Dataset found in /home/circleci/nilearn_data/haxby2001
Initializing FeatureAgglomeration object that performs the clustering#
For fMRI data taking 500 clusters is generally a good default choice.
n_clusters = 500
# Deriving voxels connectivity.
shape = mask.shape
n_x, n_y, n_z = shape[0], shape[1], shape[2]
connectivity = image.grid_to_graph(n_x=n_x, n_y=n_y, n_z=n_z, mask=mask)
# Initializing FeatureAgglomeration object.
ward = FeatureAgglomeration(n_clusters=n_clusters, connectivity=connectivity)
Making the inference with several algorithms#
First, we try to recover the discriminative pattern by computing p-values from desparsified lasso. Due to the size of the X, it’s not possible to use this method with a limit of 5 G for memory. To handle this problem, the following methods use some feature aggregation methods.
try:
beta_hat, sigma_hat, precision_diagonal = desparsified_lasso(
X, y, noise_method="median", max_iteration=1000
)
pval_dl, _, one_minus_pval_dl, _, cb_min, cb_max = desparsified_lasso_pvalue(
X.shape[0], beta_hat, sigma_hat, precision_diagonal
)
except MemoryError as err:
pval_dl = None
one_minus_pval_dl = None
print("As expected, Desparsified Lasso uses too much memory.")
'max_iter' has been increased to 199560
As expected, Desparsified Lasso uses too much memory.
Now, the clustered inference algorithm which combines parcellation and high-dimensional inference (c.f. References).
ward_, beta_hat, theta_hat, omega_diag = clustered_inference(
X, y, ward, n_clusters, scaler_sampling=StandardScaler(), tolerance=1e-2
)
beta_hat, pval_cdl, _, one_minus_pval_cdl, _ = clustered_inference_pvalue(
X.shape[0], None, ward_, beta_hat, theta_hat, omega_diag
)
Clustered inference: n_clusters = 500, inference method desparsified lasso, seed = 0,groups = False
[Parallel(n_jobs=1)]: Done 49 tasks | elapsed: 0.2s
[Parallel(n_jobs=1)]: Done 199 tasks | elapsed: 0.9s
[Parallel(n_jobs=1)]: Done 449 tasks | elapsed: 2.3s
[Parallel(n_jobs=1)]: Done 500 out of 500 | elapsed: 2.5s finished
Below, we run the ensemble clustered inference algorithm which adds a randomization step over the clustered inference algorithm (c.f. References). To make the example as short as possible we take n_bootstraps=5 which means that 5 different parcellations are considered and then 5 statistical maps are produced and aggregated into one. However you might benefit from clustering randomization taking n_bootstraps=25 or n_bootstraps=100, also we set n_jobs=2.
list_ward, list_beta_hat, list_theta_hat, list_omega_diag = (
ensemble_clustered_inference(
X,
y,
ward,
n_clusters,
groups=groups,
scaler_sampling=StandardScaler(),
n_bootstraps=5,
max_iteration=6000,
tolerance=1e-2,
n_jobs=2,
)
)
beta_hat, selected = ensemble_clustered_inference_pvalue(
X.shape[0],
False,
list_ward,
list_beta_hat,
list_theta_hat,
list_omega_diag,
fdr=0.1,
)
[Parallel(n_jobs=2)]: Using backend ThreadingBackend with 2 concurrent workers.
Clustered inference: n_clusters = 500, inference method desparsified lasso, seed = 0,groups = True
Clustered inference: n_clusters = 500, inference method desparsified lasso, seed = 1,groups = True
[Parallel(n_jobs=1)]: Done 49 tasks | elapsed: 0.2s
[Parallel(n_jobs=1)]: Done 199 tasks | elapsed: 1.0s
[Parallel(n_jobs=1)]: Done 449 tasks | elapsed: 2.6s
[Parallel(n_jobs=1)]: Done 500 out of 500 | elapsed: 2.8s finished
Clustered inference: n_clusters = 500, inference method desparsified lasso, seed = 2,groups = True
[Parallel(n_jobs=1)]: Done 49 tasks | elapsed: 0.2s
[Parallel(n_jobs=1)]: Done 49 tasks | elapsed: 0.3s
[Parallel(n_jobs=1)]: Done 199 tasks | elapsed: 1.0s
[Parallel(n_jobs=1)]: Done 199 tasks | elapsed: 1.1s
[Parallel(n_jobs=1)]: Done 449 tasks | elapsed: 2.4s
[Parallel(n_jobs=1)]: Done 449 tasks | elapsed: 2.5s
[Parallel(n_jobs=1)]: Done 500 out of 500 | elapsed: 2.7s finished
Clustered inference: n_clusters = 500, inference method desparsified lasso, seed = 3,groups = True
[Parallel(n_jobs=1)]: Done 500 out of 500 | elapsed: 2.9s finished
Clustered inference: n_clusters = 500, inference method desparsified lasso, seed = 4,groups = True
[Parallel(n_jobs=1)]: Done 49 tasks | elapsed: 0.2s
[Parallel(n_jobs=1)]: Done 199 tasks | elapsed: 1.0s
[Parallel(n_jobs=1)]: Done 449 tasks | elapsed: 2.3s
[Parallel(n_jobs=1)]: Done 500 out of 500 | elapsed: 2.6s finished
[Parallel(n_jobs=1)]: Done 49 tasks | elapsed: 0.2s
[Parallel(n_jobs=1)]: Done 199 tasks | elapsed: 1.0s
[Parallel(n_jobs=1)]: Done 449 tasks | elapsed: 2.6s
[Parallel(n_jobs=1)]: Done 500 out of 500 | elapsed: 2.9s finished
[Parallel(n_jobs=2)]: Done 5 out of 5 | elapsed: 39.1s finished
Plotting the results#
To allow a better visualization of the disciminative pattern we will plot z-maps rather than p-value maps. Assuming Gaussian distribution of the estimators we can recover a z-score from a p-value by using the inverse survival function.
First, we set theoretical FWER target at 10%.
n_samples, n_features = X.shape
target_fwer = 0.1
We now translate the FWER target into a z-score target. For the permutation test methods we do not need any additional correction since the p-values are already adjusted for multiple testing.
zscore_threshold_corr = zscore_from_pval((target_fwer / 2))
Other methods need to be corrected. We consider the Bonferroni correction. For methods that do not reduce the feature space, the correction consists in dividing by the number of features.
correction = 1.0 / n_features
zscore_threshold_no_clust = zscore_from_pval((target_fwer / 2) * correction)
For methods that parcelates the brain into groups of voxels, the correction consists in dividing by the number of parcels (or clusters).
correction_clust = 1.0 / n_clusters
zscore_threshold_clust = zscore_from_pval((target_fwer / 2) * correction_clust)
Now, we can plot the thresholded z-score maps by translating the p-value maps estimated previously into z-score maps and using the suitable threshold. For a better readability, we make a small function called plot_map that wraps all these steps.
def plot_map(
data,
threshold,
title=None,
cut_coords=[-25, -40, -5],
masker=masker,
bg_img=data.bg_img,
vmin=None,
vmax=None,
):
zscore_img = masker.inverse_transform(data)
plot_stat_map(
zscore_img,
threshold=threshold,
bg_img=bg_img,
dim=-1,
cut_coords=cut_coords,
title=title,
cmap=get_cmap("bwr"),
vmin=vmin,
vmax=vmax,
)
if pval_dl is not None:
plot_map(
zscore_from_pval(pval_dl, one_minus_pval_dl),
zscore_threshold_no_clust,
"Desparsified Lasso",
)
plot_map(
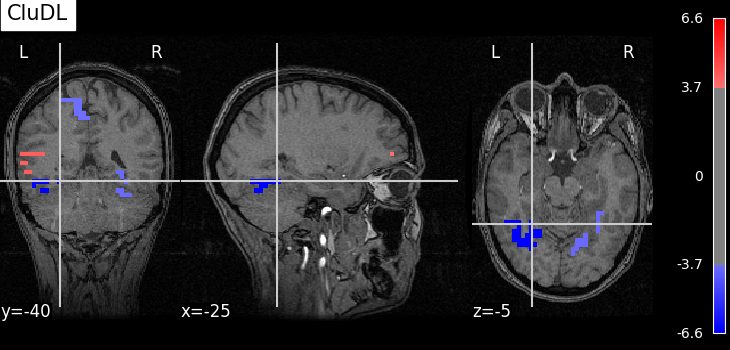
zscore_from_pval(pval_cdl, one_minus_pval_cdl), zscore_threshold_clust, "CluDL"
)
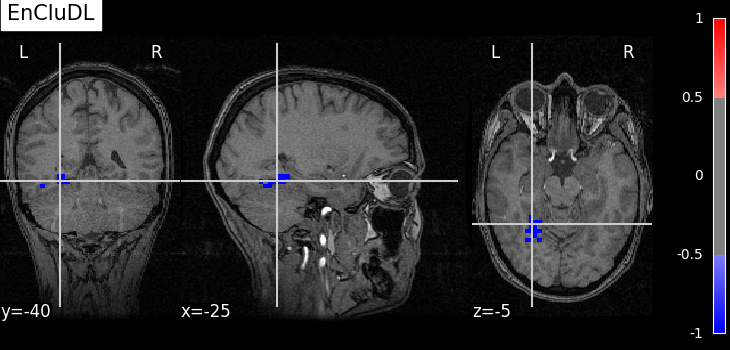
plot_map(selected, 0.5, "EnCluDL", vmin=-1, vmax=1)
# Finally, calling plotting.show() is necessary to display the figure when
# running as a script outside IPython
show()
Analysis of the results#
As advocated in introduction, the methods that do not reduce the original problem are not satisfying since they are too conservative. Among those methods, the only one that makes discoveries is the one that threshold the SVR decoder using a parametric approximation. However this method has no statistical guarantees and we can see that some isolated voxels are discovered, which seems quite spurious. The discriminative pattern derived from the clustered inference algorithm (CluDL) show that the method is less conservative. However, some reasonable paterns are also included in this solution. Finally, the solution provided by the ensemble clustered inference algorithm (EnCluDL) seems realistic as we recover the visual cortex and do not make spurious discoveries.
References#
Total running time of the script: (2 minutes 37.634 seconds)